POMDPS
On-Robot Bayesian Reinforcement Learning for POMDPsПодробнее

Time-Varying POMDPsПодробнее

Efficient Sampling in POMDPs with Lipschitz Bandits for Motion Planning in Continuous SpacesПодробнее

Autonomy Talks - Zachary Sunberg: Breaking the curse of dimensionality in POMDPsПодробнее

Offline POMDPs LectureПодробнее

Connections between POMDPs and partially observed n-player mean-field games, Bora YongacogluПодробнее

Preference learning for guiding the tree search in continuous POMDPs (CoRL2023)Подробнее

PGP:Preference learning for guiding the tree search in continuous POMDPs (CoRL2023)Подробнее

Computationally Efficient Learning of POMDPs — Noah Golowich | 2023 Hertz Summer WorkshopПодробнее

Task-Directed Exploration in Continuous POMDPs for Robotic Manipulation of Articulated ObjectsПодробнее

CSE574:Week 13: Factored Belief State STRIPS Planning + POMDPsПодробнее

Recurrent Model-Free RL Can Be a Strong Baseline for Many POMDPs (ICML 2022)Подробнее

Джулия лучше JAX для машинного обучения? | Поговорим о Джулии #19Подробнее

[05x13] SARSA и алгоритмы Q-обучения с POMDPs.jl | Джулия Армирование, машинное обучениеПодробнее
![[05x13] SARSA и алгоритмы Q-обучения с POMDPs.jl | Джулия Армирование, машинное обучение](https://img.youtube.com/vi/ITzRizRpHzI/0.jpg)
[05x12] Марковский процесс принятия решений (MDP) с POMDPs.jl | Джулия Армирование, машинное обучениеПодробнее
![[05x12] Марковский процесс принятия решений (MDP) с POMDPs.jl | Джулия Армирование, машинное обучение](https://img.youtube.com/vi/GXnCm_6uyeM/0.jpg)
Recurrent Model-Free RL is a Strong Baseline for Many POMDPsПодробнее

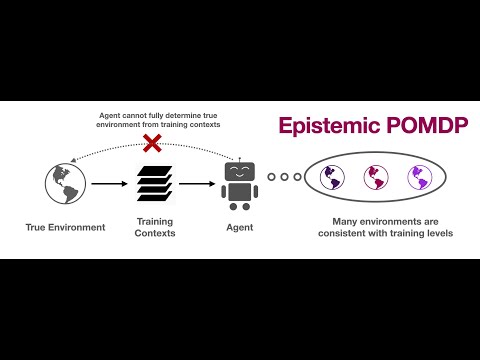
Почему обобщение в RL сложно: эпистемические POMDP и неявная частичная наблюдаемостьПодробнее
Проверка черного ящика | Принятие решений в условиях неопределенности с использованием POMDPs.jlПодробнее

Имитационное обучение | Принятие решений в условиях неопределенности с использованием POMDPs.jlПодробнее

Глубокое обучение с подкреплением | Принятие решений в условиях неопределенности с использованием POMDPs.jlПодробнее
